 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSame or Not? Enhancing Visual Perception in Vision-Language Models
Dec 29, 2025Vision-language models (VLMs) excel at broad visual understanding but remain coarse-grained, exhibit visual biases, and miss subtle visual details. Existing training corpora reinforce this limitation by emphasizing general recognition ("Is it a cat or a dog?") over fine-grained perception. To address this, we introduce a new training corpus and task designed to enhance the perceptual abilities of VLMs. TWIN is a large-scale dataset of 561,000 image-pair queries that task models to determine whether two visually similar images depict the same object, encouraging attention to nuanced visual cues. The dataset spans a diverse range of everyday objects across contexts, viewpoints, and appearances. Fine-tuning VLMs on TWIN yields notable gains in fine-grained recognition, even on unseen domains such as art, animals, plants, and landmarks. To quantify these gains, we introduce FGVQA, a benchmark suite of 12,000 queries that repurposes fine-grained recognition and retrieval datasets from multiple domains. While existing VLMs struggle on FGVQA, when fine-tuned on TWIN they improve by up to 19.3%, without compromising performance on general VQA benchmarks. Finally, our TWIN dataset scales favorably with object annotations, and our analysis shows that scale is key to performance. We envision TWIN as a drop-in addition to open-source VLM training corpora, advancing perceptual precision of future models. Project webpage: https://glab-caltech.github.io/twin/
Exposing DeepFakes via Hyperspectral Domain Mapping
Nov 13, 2025

Modern generative and diffusion models produce highly realistic images that can mislead human perception and even sophisticated automated detection systems. Most detection methods operate in RGB space and thus analyze only three spectral channels. We propose HSI-Detect, a two-stage pipeline that reconstructs a 31-channel hyperspectral image from a standard RGB input and performs detection in the hyperspectral domain. Expanding the input representation into denser spectral bands amplifies manipulation artifacts that are often weak or invisible in the RGB domain, particularly in specific frequency bands. We evaluate HSI-Detect across FaceForensics++ dataset and show the consistent improvements over RGB-only baselines, illustrating the promise of spectral-domain mapping for Deepfake detection.
Remote Labor Index: Measuring AI Automation of Remote Work
Oct 30, 2025AIs have made rapid progress on research-oriented benchmarks of knowledge and reasoning, but it remains unclear how these gains translate into economic value and automation. To measure this, we introduce the Remote Labor Index (RLI), a broadly multi-sector benchmark comprising real-world, economically valuable projects designed to evaluate end-to-end agent performance in practical settings. AI agents perform near the floor on RLI, with the highest-performing agent achieving an automation rate of 2.5%. These results help ground discussions of AI automation in empirical evidence, setting a common basis for tracking AI impacts and enabling stakeholders to proactively navigate AI-driven labor automation.
LDFaceNet: Latent Diffusion-based Network for High-Fidelity Deepfake Generation
Aug 04, 2024



Over the past decade, there has been tremendous progress in the domain of synthetic media generation. This is mainly due to the powerful methods based on generative adversarial networks (GANs). Very recently, diffusion probabilistic models, which are inspired by non-equilibrium thermodynamics, have taken the spotlight. In the realm of image generation, diffusion models (DMs) have exhibited remarkable proficiency in producing both realistic and heterogeneous imagery through their stochastic sampling procedure. This paper proposes a novel facial swapping module, termed as LDFaceNet (Latent Diffusion based Face Swapping Network), which is based on a guided latent diffusion model that utilizes facial segmentation and facial recognition modules for a conditioned denoising process. The model employs a unique loss function to offer directional guidance to the diffusion process. Notably, LDFaceNet can incorporate supplementary facial guidance for desired outcomes without any retraining. To the best of our knowledge, this represents the first application of the latent diffusion model in the face-swapping task without prior training. The results of this study demonstrate that the proposed method can generate extremely realistic and coherent images by leveraging the potential of the diffusion model for facial swapping, thereby yielding superior visual outcomes and greater diversity.
Learning to Enhance Visual Quality via Hyperspectral Domain Mapping
Feb 10, 2021
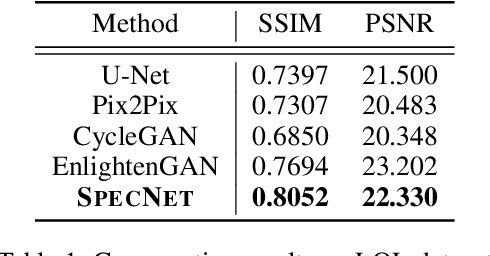
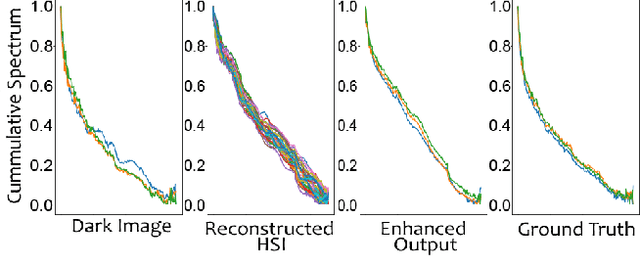

Deep learning based methods have achieved remarkable success in image restoration and enhancement, but most such methods rely on RGB input images. These methods fail to take into account the rich spectral distribution of natural images. We propose a deep architecture, SpecNet, which computes spectral profile to estimate pixel-wise dynamic range adjustment of a given image. First, we employ an unpaired cycle-consistent framework to generate hyperspectral images (HSI) from low-light input images. HSI is further used to generate a normal light image of the same scene. We incorporate a self-supervision and a spectral profile regularization network to infer a plausible HSI from an RGB image. We evaluate the benefits of optimizing the spectral profile for real and fake images in low-light conditions on the LOL Dataset.
Domain-Aware Unsupervised Hyperspectral Reconstruction for Aerial Image Dehazing
Nov 07, 2020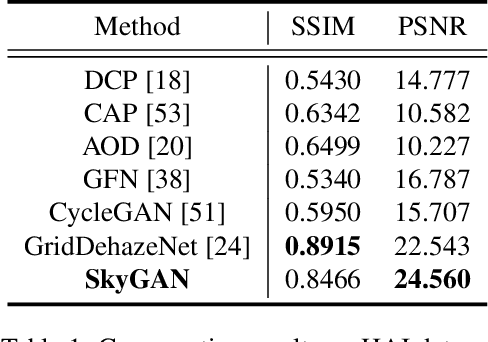

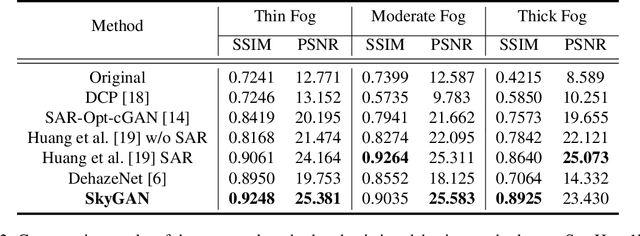
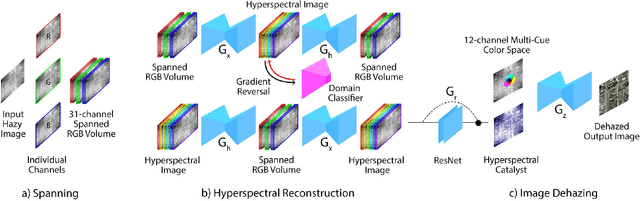
Haze removal in aerial images is a challenging problem due to considerable variation in spatial details and varying contrast. Changes in particulate matter density often lead to degradation in visibility. Therefore, several approaches utilize multi-spectral data as auxiliary information for haze removal. In this paper, we propose SkyGAN for haze removal in aerial images. SkyGAN consists of 1) a domain-aware hazy-to-hyperspectral (H2H) module, and 2) a conditional GAN (cGAN) based multi-cue image-to-image translation module (I2I) for dehazing. The proposed H2H module reconstructs several visual bands from RGB images in an unsupervised manner, which overcomes the lack of hazy hyperspectral aerial image datasets. The module utilizes task supervision and domain adaptation in order to create a "hyperspectral catalyst" for image dehazing. The I2I module uses the hyperspectral catalyst along with a 12-channel multi-cue input and performs effective image dehazing by utilizing the entire visual spectrum. In addition, this work introduces a new dataset, called Hazy Aerial-Image (HAI) dataset, that contains more than 65,000 pairs of hazy and ground truth aerial images with realistic, non-homogeneous haze of varying density. The performance of SkyGAN is evaluated on the recent SateHaze1k dataset as well as the HAI dataset. We also present a comprehensive evaluation of HAI dataset with a representative set of state-of-the-art techniques in terms of PSNR and SSIM.